Building the Future: The Modern MLOps Pipeline for Scaling AI

Building the Future: The Modern MLOps Pipeline for Scaling AI
Watch a presentation version of this blog post here - Accelerating AI Deployment and Adoption
Hello again, AI aficionados! It’s Dan from gravityAI. Today, we’re diving into the MLOps pipeline—the backbone of any AI operation.
Key Components of MLOps: According to the Gartner MLOps Playbook, a good MLOps pipeline provides the tech stack necessary for role-specific guidance, automation, and scalable pipelines.
Why MLOps Matters: MLOps ensures your AI models are not just deployed but monitored, updated, and managed.. Continuous lifecycle management is key for maintaining performance and compliance.
Implementing MLOps with gravityAI: gravityAI provides a core function in this pipeline: acting as your model repository and deployment capabilities.
Lets start with the essentials of data science:
1. Data Science Toolbox:
- Description: The starting point where data scientists work on model development using various tools and frameworks.
- Tools: Jupyter, Zeppelin, VS Code, PyCharm.
- Function: It’s like your toolbox filled with all the gadgets and gizmos a data scientist needs to build and experiment with models.
2. Logical Data Warehouse (DW):
- Description: A centralized repository that consolidates data from various sources, making it accessible for analysis and modeling.
- Tools: Amazon Redshift, Google BigQuery, Snowflake.
- Function: Think of it as your data vault, and the other necessary data capabilities in order to make scalable calls to a database. This section in reality is a massive diagram all of its own.
3. Code Repository:
- Description: A version-controlled storage space for code, ensuring collaboration and traceability.
- Tools: GitHub, GitLab, Bitbucket.
- Function: This is your code library, where every bit of raw code is stored, versioned, and ready to be collaborated on with permissioned users.
4. Model Training:
- Description: The process where data is used to train machine learning models.
- Tools: TensorFlow, PyTorch, Scikit-learn, Spark MLlib.
- Function: It’s the training ground where your models learn to become the champions of data prediction.
These four functions represent the R and D portion of the pipeline. Typically this is where traditional data science activities take place. However, these are not sufficient for a truly scalable pipeline of building and utilizing AI. While necessary, this will only get an organization to a point of PoC, not true production.
https://cdn.gx-staging.com/rnd_pipeline.png
{kind=link}
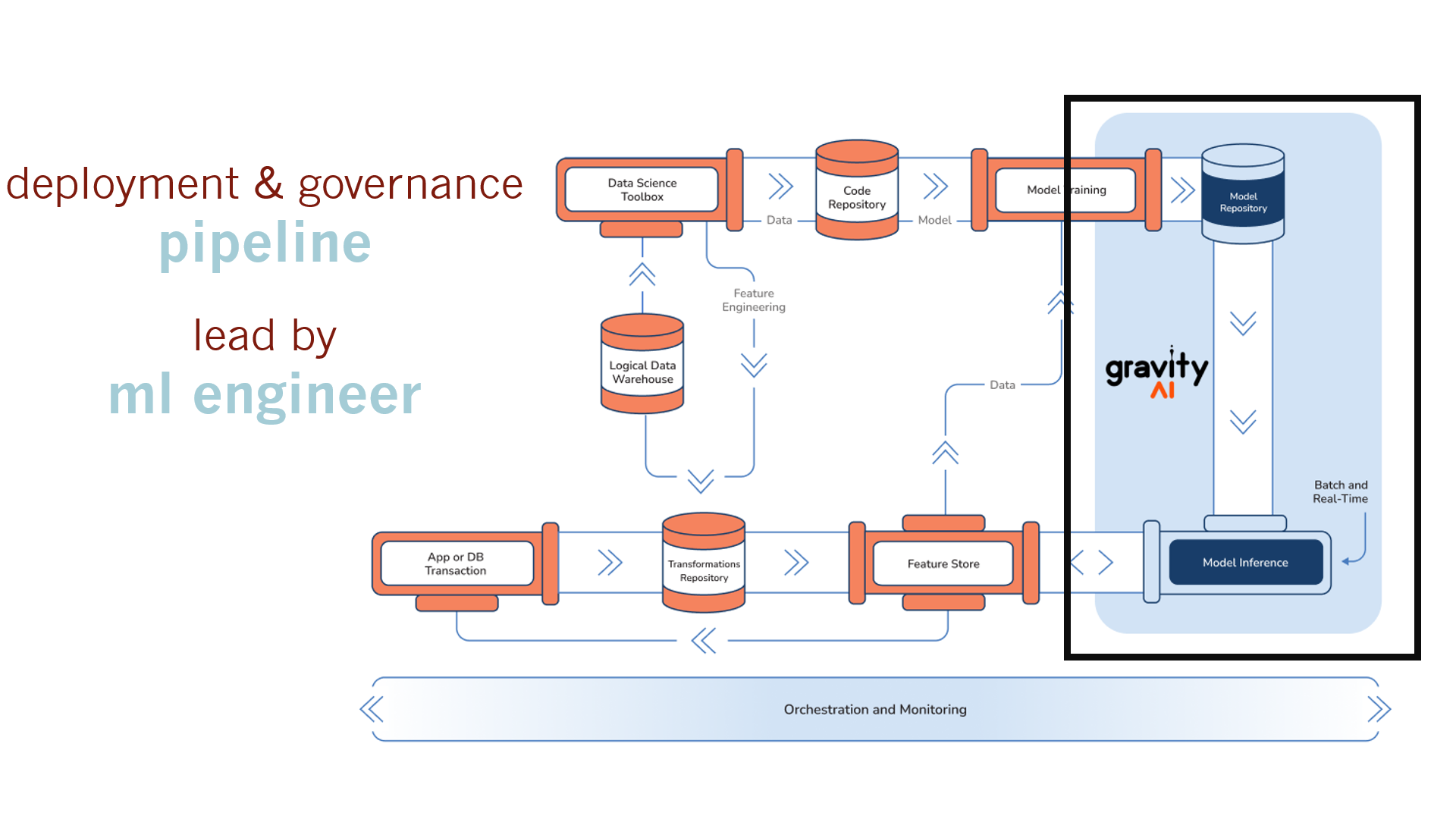
The next step in the puzzle, is how and organization moves from just PoC capabilities to navigating compliance and launching models effortlessly through a model repository and deployment pipeline. This is often a neglected step, but is now the most critical in the process, and happens to be what gravityAI does better than anyone else - store production ready and compliance focused models, and automate the deployment process.
1. Model Repository:
- Description: A storage space for trained models, ensuring they are versioned and can be easily accessed for deployment, as well as audited for compliance.
- Tools: gravityaAI, MLflow
- Function: This is your production ready model vault, where versioned models have compliance ready documentation, and are hardened into stable, containerized modules using docker/kubernetes.
2. Model Inference:
- Description: The process of deploying trained models to make predictions on new data in real-time or batch mode.
- Tools: gravityAI, KFServing, TensorFlow Serving
- Function: This is where and how your models prove their worth by making real-time predictions in the real-world for your end users.
3 . Deployment Pipeline:
- Description: The automated workflow that takes models from training to deployment, ensuring smooth transitions and continuous integration.
- Tools: gravityAI
- Function: It’s the assembly line that ensures models move from development to deployment seamlessly. Well oiled pipelines like gravityAI take what used to be a month of work and reduce it to hours.
https://cdn.gx-staging.com/deployment_pipeline.png
{kind=link}
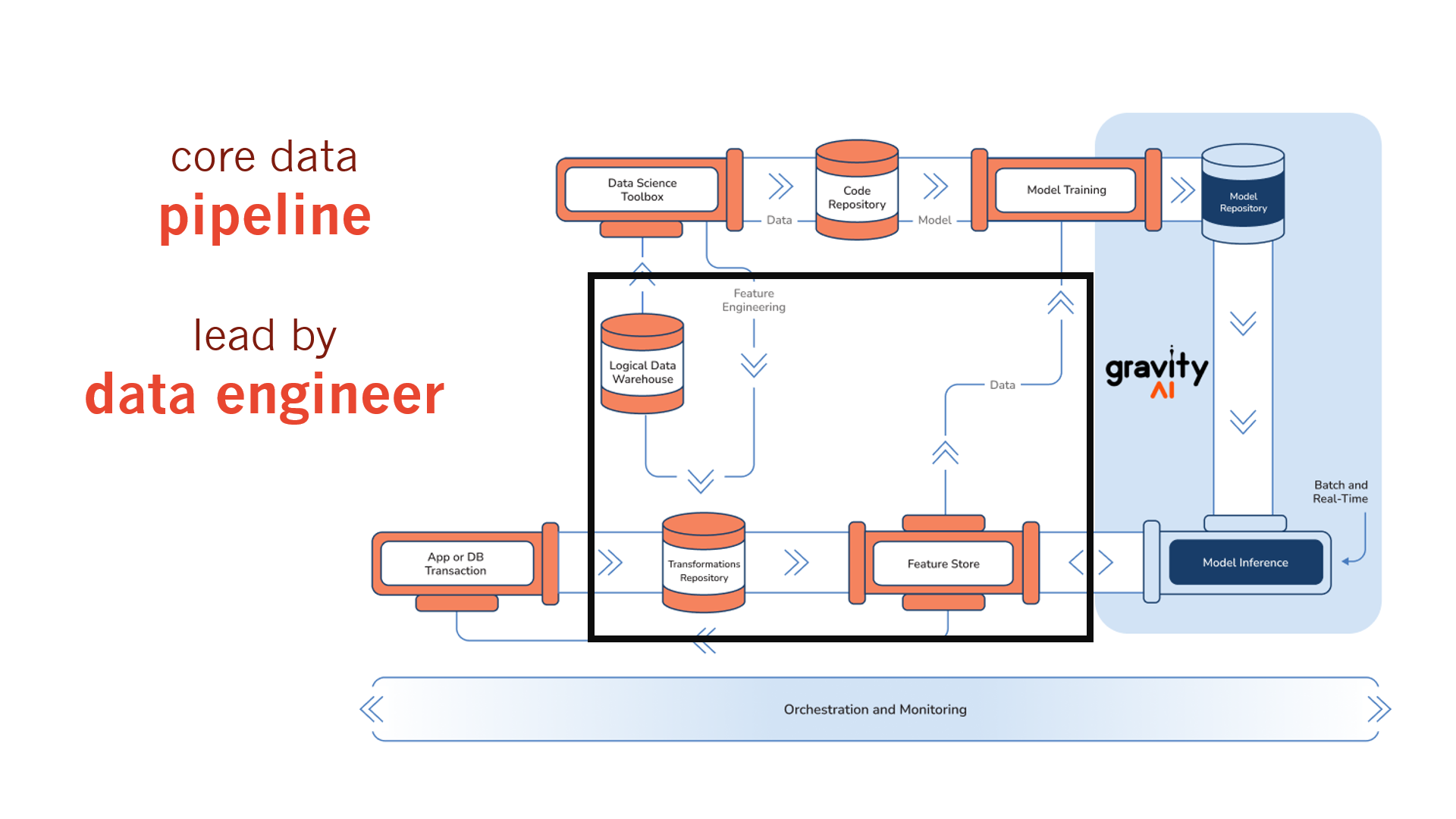
Finally, we get to the data pipeline which allows organizations to customize models (often pre-trained models) with speed.
1. Data Pipeline:
- Description: Manages the flow of data from various sources to the data warehouse and then to the model training environment.
- Tools: Apache Kafka, Apache Nifi, Airflow.
- Function: It’s the bloodstream of your data operations, ensuring data flows smoothly where it’s needed.
2. Transformations Repository:
- Description: Stores the scripts and logic used to transform raw data into a format suitable for model training.
- Tools: DBT (Data Build Tool), Talend, Apache Beam.
- Function: Think of it as the data kitchen, where raw ingredients are transformed into delicious, model-ready datasets.
3. Feature Store:
- Description: A centralized storage for features used in model training, ensuring consistency and reusability.
- Tools: Feast, Hopsworks, Tecton.
- Function: It’s like the spice rack of your kitchen, where all the key ingredients (features) are stored for easy access and use.
4. Orchestration and Monitoring:
- Description: Manages the entire MLOps pipeline, ensuring each component works harmoniously and performance is continuously monitored.
- Tools: Airflow, Kubeflow Pipelines, Prometheus, Grafana.
- Function: This is the command center, where every operation is monitored, and adjustments are made to keep everything running smoothly.
https://cdn.gx-staging.com/data_pipeline.png
{kind=link}
A modern MLOps pipeline is like the ultimate machine, each part playing a vital role in your mission to expand your AI maturity and crush your competition. If you want to learn more about how gravityAI equips your institution with the tools and processes needed to excel in AI, reach out HERE 🌟
For more on how to leverage AI in finance, check out our previous posts on the Evident AI Index HERE and how gravityAI can boost your Evident AI ranking HERE.