We Built a Data Science Task and Skills Extractor

Whether you are a recent graduate entering the data science job market for the first time, a seasoned professional on the hunt for the next big opportunity, or just someone who wants to be "in the know" of all things data science related, three big questions that may come to mind are the following:
1. What kind of problems are data scientists being hired to do?
2. What are the most common skills posted in job descriptions?
3. What are typical data scientist skills vs data engineer skills vs data analyst skills?
We decided to take matters into our own hands and find the answers to these questions in addition to a few more. This post details an analysis we did on over 26,000 data science job listings and the findings that emerged from it.
You can play around with the data science job description parser we created by clicking HERE.
Gathering the data
No analysis be possible without data! To gather the data need for the project we turned to the most obvious resource… job posting websites. We scraped data science listings from Indeed, CareerBuilder, Glassdoor, Snagajob, in addition to several other job boards. We also found publicly available datasets containing data science job descriptions from Kaggle and several other websites. Combined we collected in total 57,808 job postings that dated as early as 2019 and as recent as mid-2022. After removing duplicate data and listings not related to data science, we were left with roughly 26,000 job postings.
Exploring the structure of a Job Post
We started the analysis by exploring the dataset in search of subjects commonly mentioned in job posts. Our initial thought was these subjects may also be indicative of problems data scientists are tasked to solve. For this we turned to topic modeling.
Topic modeling is an unsupervised machine learning technique used to discover abstract concepts present within a collection of documents. A concept is defined as a collection of words that frequently appear in documents about a particular subject. For instance, we would expect the words "football" and "athlete" to appear more in documents about sports than in documents about the environment. Because documents typically mention multiple topics in varying degrees, topic models present topic predictions for a document as weightings or percentages of topics present in the document. This is analogous to the nutrients and ingredients displayed on the nutrition facts label for a food product.
The topic modeling method we employed was Latent Dirichlet Allocation or LDA for short.
As considered standard practice when doing NLP work, we performed some preprocessing on the text before performing the topic modeling. We began by removing stop words from the job descriptions. Stop words are words that occur so frequently in text that they add very little meaning to an analysis. In the English language, these include words like "a", "because", "or", and "but". We also lemmatized the words in the job descriptions. Lemmatization is a preprocessing method that involves reducing words to their root word, or lemma. You can read more about the process here.
Because LDA works best with documents that are medium to large in length, we needed to remove job descriptions that were too short. From our research, the minimum recommended size for job descriptions is 300 words. We therefore removed job descriptions that were below this number.
Using LDA we were able to uncover 25 topics within the job postings. Below are word clouds of the top 200 words for each of the topics.
https://cdn.gx-staging.com/Data_Science_Skills.png
LDA did a good job at identifying several application areas within data science. Topic 18 for example contains words related to digital marketing and advertising. Topic 10 and Topic 4 describe almost similar concepts, the former being about Aerospace, Defense, and the latter being about Government Program management. Other application areas that were identified include:
{kind=link}
- Banking and Financial Services (Topic 22)
- Investment Management (Topic 5)
- Healthcare (Topic 24)
- Biotechnology (Topic 20)
- Life Sciences (Topic 6)
- KPMG Advisory (Topic 9)
- United Health Group (Topic 1)
- Insurance and Hospitality (Topic 12)
- Using LDA we were also able to identify topics related to a few data science practices and concepts. These include:
- Data Governance (Topic 3)
- Data Engineering (Topic 14)
- Data Reporting and Dashboarding (Topic 15)
- AI/ML Tools and Modeling (Topics 16 and 25)
- Statistical Analysis (Topic 23)
We also identified topics related to typical components of a job description. Topic 8 for example contained words related to the diversity and inclusion statement that is commonly included in job descriptions. Company perks and benefits also has a topic of its own as well (Topic 21).
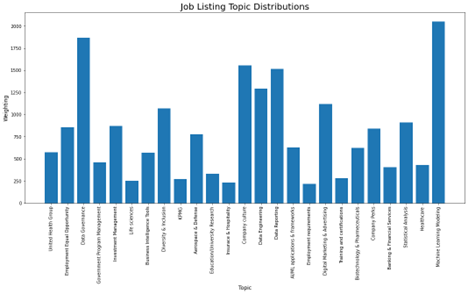
To better understand how each topic was distributed across the entire dataset, we added up all the topic weightings for each job description and produced the bar plot below.
https://cdn.gx-staging.com/Job_Listing_Top_Distributions.png
{kind=link}
Machine learning modeling was the most dominant topic in the dataset, which probably isn't a big surprise for anyone reading this post. Following behind it was data governance, data engineering, data reporting, and company culture.
The topic model provided great insight into the concepts embedded in our job description dataset and some of the things data scientists are expected to do at a high level. To extract deeper insights on the tasks companies are seeking data scientists to work on we implemented the approach described in the next section.
Data Science Task Extraction
To identify data science tasks from a job description, we first took a step back and defined the information we wanted to extract.
We defined a data science task or problem as an action phrase that is related to a concept in data science.
Examples of a data science problems pulled from actual job descriptions are the following:
- Implement ETL workflows and technologies
- Translate business requirements and models into feasible and acceptable master data management designs
- Design, build and investigate deep learning architectures for processing speech
Using spaCy's nlp pipeline, we extracted action phrases from each job description. The action phrases begin with a verb and end with either an adposition or punctuation. The words in the extracted phrases were also lemmatized for later processing. Here's a sliver of the action phrases we extracted:
"support a grow analytic team to service both an operational modernization program and strategy to leverage datum to improve member health outcome"
"understand the need"
"determine how to good translate + model transactional datum"
"possess a curious and passionate analytical mindset"
"work"
"assist"
"build an entirely new set"
"develop a deep understanding"
"build"
"optimize an analytic layer that will enable our analyst to do more and provide easy access"
"provide design and performance optimization as analytic scale"
"build"
"maintain"
"support custom analytic pipeline"
"work"
"curate requirement and understand how they would like to view the datum"
"write high quality"
"require qualification"
"simplify complex datum set"
"understand business strategy"
"provide consultative business analysis"
"create insightful"
"thrive"
"base environment"
"collect"
"disseminate significant amount"
"work"
"prefer"
The extraction resulted in a mixture of both relevant and irrelevant phrases. We looked for another unsupervised learning method to help us make sense of the phrases we collected and weed out unwanted phrases. The method we chose is called Gibbs Sampling Dirichlet Multinomial Mixture, or GSDMM for short. It's a topic modeling algorithm that works much better than LDA at clustering very short texts like tweets and Amazon product reviews.
Additional processing was done on the action phrases before performing the clustering. We removed the stop words from the phrases and filtered out phrases that were less than three words in length. This was done to ensure that the clustering provided meaningful results.
GSDMM was able to identify 38 clusters. After examining the clusters, we determined 16 of them to be relevant to data science. The following are brief descriptions of the clusters and examples of phrases for each.
Cluster #1: Project Management, Leadership, and Cross Functional Collaboration
The phrases in this cluster pertain to tasks related to managing and executing, leading teams, and working on cross functional teams. Phrases related to providing mentorship was also part of this cluster.
Examples of phrases from this cluster are:
"lead ml strategy and road map planning"
"manage and execute the successful delivery"
"include cross - functional project management"
"construct analysis and work cross - functionally with manager to integrate result"
"think lead datum science solution"
"experience lead technical team"
"manage data science team and help drive the organization?s technology vision"
Cluster #2: AI/ML Model Development
This cluster contained phrases about tasks related to developing and applying machine learning models.
Examples of phrases from this cluster are:
"develop supervised and unsupervised learning model"
"leverage experience to scale and validate model"
"implement machine learning pipeline that improve autodesk?s evidence"
"build machine learning and ai algorithm that be the core"
"back startup that be use artificial intelligence and machine learning to predict the success"
"develop machine learn centric software application"
Cluster #3: Requirements Analysis
Tasks related to performing requirements analysis, identifying business use cases, identifying issues, and addressing business needs belong to this cluster.
Examples of phrases from this cluster are:
"develop business technology roadmap that drive application roadmap and deliver quality solution that meet business need"
"propose solution that can improve customer?s ability to succeed"
"assess customer requirement and translate they to appropriate deliverable"
"capture ability to translate engagement objective"
"conceptualize and designing model to address business need"
"anticipate client need and formulate solution"
Cluster #4: Product Enhancements
Tasks that involved implementing solutions that improved the quality of a product or service were grouped into this cluster.
Examples of phrases from this cluster are:
"target solution that dramatically improve the performance and cost"
"drive recommendation to improve siri 's user experience"
"lead brand and high product quality"
"develop solution that help deliver significant value"
"create high impact solution improve business"
"architecte and execute strategic partnership and platform capability to drive growth and business diversification"
"support a grow analytic team to service both an operational modernization program and a strategy to leverage datum to improve member health outcome"
Cluster #5: Exploratory Data Analysis
This cluster contained phrases about tasks related to collecting, analyzing, interpreting, and manipulating data. Tasks related to creating data visualizations to communicate insights to stakeholders were also grouped here.
Examples of phrases from this cluster are:
"manipulate datum and draw insight"
"manipulate datum set and build statistical model"
"experience visualize / present datum"
"analyze data set to extract meaningful trend must have good experience use statistical" "programming language"
"transform structured and unstructured data set ability to produce meaningful and actionable" "report strong analytical skill and strong attention"
"use intuitive datum visualization technique"
"gather and compile datum relate"
Cluster #6: Analytics Software Development and Evaluation
This cluster appears to pertain to tasks related to developing, utilizing, or evaluating analytics software tools or products.
Examples of phrases from this cluster are:
"leverage datum and analytic to innovatively bring well product"
"improve our next generation online analytic platform"
"investigate new and develop technology as they appear"
"emerge technology and open source tool"
"deliver a viable solution use ai / ml"
"develop analytic sub - practice"
"include evaluate new technology to incorporate"
Cluster #7: Documentation, Technical Reports, and Statistical Testing
Statistical testing, preparing documentation, producing technical reports, and other similar tasks of that nature belong to this cluster.
Examples of phrases from this cluster are:
"write script to produce output product or report"
"provide input to software documentation and user guide"
"develop internal a / b testing procedure"
"run a / b test and familiar"
"collect field datum to reproduce unexpected result"
"rank ml and ai conference and journal publication"
"prepare product to describe and document finding and activity"
"write thorough test and documentation"
"prepare detailed technical report"
Cluster #8: Root Cause Analysis
This cluster contains tasks related to root cause analysis, risk identification and remediation, trend analysis, defect identification, and anomaly detection.
Examples of phrases from this cluster are:
"detect fraudulent electronic transaction / usage"
"uncover trend and find root cause"
"identify model risk technical writing part be important year"
"require as long as they can identify the model and risk it doesn?t have to be industry specific"
"propose corrective action to improve profitability"
"monitor business issue and request"
"conduct root cause analysis"
"detect pattern and recommend solution"
"identify and resolve data analytic"
"mitigate compliance risk and ensure audit"
Cluster #9: Data Pipeline Development
Any task that involves developing scalable distributed systems, writing production quality code, and building data pipelines belong to this cluster.
Examples of phrases from this cluster are:
"workflow that incorporate both batch and streaming analytic"
"include database and real time streaming"
"build large systematic report and one"
"create datum architecture and query they"
"model a decision and build a process and interface to actually generate the feature we need to automate a decision"
"develop or implement enterprise class datum analytic and bi solution"
"create datum analysis and analytic pipeline that improve not only the underlying ml algorithm but also the product and the user 's experience"
"build predictive model and create scalable solution to support new business"
Cluster #10: Strategic Business Decision Making
Included in this cluster are tasks related to performing analysis in support of strategic decision making and providing insights and recommendations to a business.
Examples of phrases from this cluster are:
"maintain dashboard to show key impact"
"support strategic and tactical decision making"
"generate daily to help the business make smart decision"
"discover valuable insight hide"
"provide deep analysis and valuable insight to unlock opportunity and drive inform business decision"
"help our customer achieve their goal"
"help shape the overall advanced analytic strategy"
"provide key insight and recommendation"
"assist mapmg to make strategic data"
"interpret analysis and develop action plan accordingly"
Cluster #11: Performance Monitoring, Quality Assurance, and Planning
This cluster includes tasks related to performance monitoring, planning, and quality assurance.
Examples of phrases from this cluster are:
"measure progress and adjust performance accordingly"
"document observation and establish predictability and trend report to develop daily and operational plan"
"prepare project plan and weekly status report"
"track disinformation and foreign influence campaign online"
"provide maintenance event and associate spare part forecast"
"develop executive communication and present analysis and insight to client 's senior leadership"
"perform ad hoc analysis and support special project"
"develop process to monitor and analyze model performance and make update as need"
Cluster #12: Support and Consultation
Tasks related to providing consultations and support to different teams or departments belong to this cluster.
Examples of phrases from this cluster are:
"apply our operational experience and development knowledge to provide unique subject matter expertise and to build highly effective mission critical system"
"provide consultative business analysis"
"direct and provide technical support"
"provide estimation and planning support"
"contribute analytical expertise wherever it be most need to move textio forward"
"provide analytical and technical support"
"apply your expertise to prepare internal and external"
"provide bioinformatic and statistical guidance"
"provide support and expertise to help u.s . and canada branch team deliver an ideal client experience"
"expect to bring extensive technical datum analytic experience and expertise"
Cluster #13: Health and Biotechnology
Health, clinical, and biotechnology related tasks belong to this cluster.
Examples of phrases from this cluster are:
"accelerate critical drug and medical device development"
"do exploration and early prototyping include faithful such"
"develop a novel diagnostic platform call the indicator cell assay platform"
"select and create method to identify differentially express gene use rna expression datum"
"improve forecast method and accuracy communicate the effect that trial design element"
"include understand clinical pharmacology component"
"develop novel digital biomarker"
"perform oncology clinical research"
"use human genetic information to develop novel medicine"
"design and execute control experiment to quantify the effect"
"develop new research tool to help define the mechanism underlie cell function and disease"
Cluster #14: Data Mining, Statistical Analysis, and Predictive Modeling
Grouped in this cluster are activities related to data mining, statistical analysis, and predictive modeling.
Examples of phrases from this cluster are:
"use advanced statistical analysis include data reduction technique"
"implement and utilize advanced statistical and machine learning technique"
"improve exist empirical technique use"
"have datum engineering and statistical modeling skill to conduct validation"
"develop sophisticated advanced analytic model"
"relate software leverage strong math skill and statistical knowledge"
"define and develop predictive modeling initiative and building"
"build software that apply proprietary machine learning model to help manage a core problem" "that all mid - market business face"
"apply statistical or machine learn knowledge"
Cluster #15: Process Improvement and Best Practices
This cluster includes tasks related to process improvement, supporting good practices, and quality assurance.
Examples of phrases from this cluster are:
"support analytic good practice"
"design and ensure good practice be apply"
"enhance data collection procedure to include information that be relevant"
"train various model and do quality check"
"automate continuous quality control"
"code practice include good design documentation"
"maintain good configuration and data management method"
"continuously generate idea and build tool to improve data collection quality and process"
"establish data science framework select feature"
"recommend the most effective data science approach"
"understand and apply software design principle and architectural good practice"
Cluster #16: Database Queries and Scripting
Finally, this cluster contains activities related to performing database queries and writing scripts.
Examples of phrases from this cluster are:
"query database and use statistical computer language"
"use query language such good apply statistic skill"
"write clean performant reusable code to perform repeatable analysis and to train and deploy model"
"write query and perform ad"
"write high performance python code"
"use relational database and analytic"
"perform system analysis and programming task to maintain and control the use"
"utilize advanced sql skill to critically inspect and analyze large"
"write sas program source code"
Visualizing Extracted Tasks
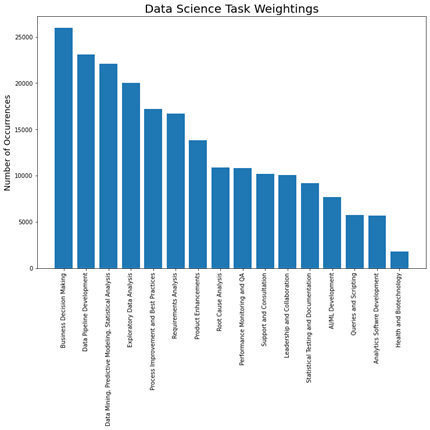
Using the model developed in the previous section, we extracted relevant data science tasks from each job description and tallied up the number of tasks belonging to each category.
https://cdn.gx-staging.com/Data_Science_Task_Weightings.png
{kind=link}
Pictured above is a bar chart of the number of mentions of each type of task in the job descriptions. As shown in the figure, Business Decision Making, Data Pipeline Development, and Data Mining, Predictive Modeling and Statistical Analysis are the most prevalent tasks in the dataset.
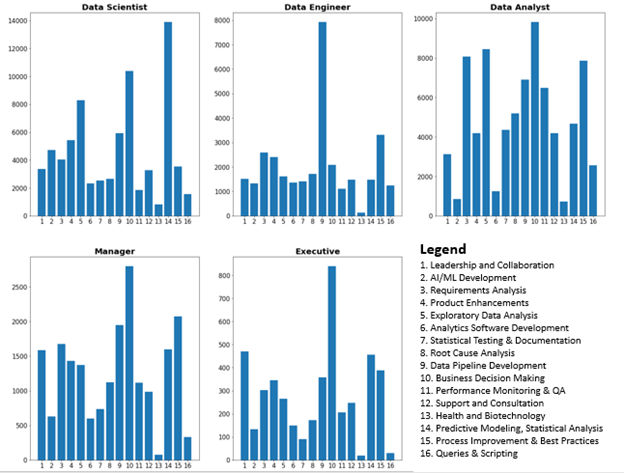
An even more interesting picture emerges when the task counts are segmented by job title.
https://cdn.gx-staging.com/Tasks_by_job_title.png
{kind=link}
Right away we notice some distinct differences in the tasks prescribed to various data roles:
- Job listings for Data Engineers for instance tend to contain more tasks around developing production ready software code than anything else.
- Data Scientist job listings tend to emphasize data mining, predictive modeling, and statistical analysis related tasks.
- Data Analyst job descriptions tend to center around requirements analysis, performing data analysis, and supporting strategic decision making.
- While manager and executive type job descriptions make up a much smaller percentage of the dataset, you can notice more relative emphasis on leadership and business strategy compared to the job descriptions for data scientists, data engineers, and data analysts.
Wait…there's more! Using the LDA topic model produced in the last section we can group each job listing into one of the 25 discovered topics, based on whichever topic is the most prevalent. When we segmented the task counts by topic, we were able to produce this massive graphic:
https://cdn.gx-staging.com/Jod_listing_grouping_by_topic.png
{kind=link}
Wowza! There's a lot of information that can be gained from the chart above. We'll just point out a few things that stick out and leave it up to you, the reader, to find more:
- Job descriptions that fall under the Banking & Financial Services topic (topic 22) appear to have a noticeable emphasis on tasks related to Root cause analysis (cluster 8), compared to other topics in the dataset.
- Job descriptions strongly associated with the AI/ML applications & frameworks topic (topic 16) lean heavily on tasks related to AI/ML model development (cluster 2) and data mining, predictive modeling, and statistical analysis (cluster 14)
- Data Governance job listings (topic 3) emphasize both requirements analysis tasks (cluster 3) and process improvement and best practices tasks (cluster 15)
With the task extractor we were able to uncover interesting insights on what companies are hiring data scientists to do. We then became curious about the data science skills involved in performing these tasks. To satisfy our curiosity we developed a skills extraction model.
Data Science Skills Extraction
Our approach to creating the skills extraction model starts with first extracting noun phrases from each job description. Noun phrases are groups of words that function like nouns. We once again utilized the nlp pipeline provided by spaCy to extract the phrases.
Here's a few of the noun phrases that were collected:
"a small challenging and entrepreneurial environment"
"terminal interoperability certification evaluation plans"
"joint modeling"
"complex sql"
"the center policies"
"r and or python programing languages"
"component manufacturer"
"a plus job descriptionworking"
"data architecture skills"
"the reporting platforms"
"local health authorities"
"may 2 2019 role number"
"managing fintech projects"
"meticulous ongoing quality assurance"
"the major aerospace"
"developing goals"
Each phrase was then assigned the label "skill" or "no skill" depending on whether it mentioned a hard skill. We considered a hard skill to be any skill applied in data science.
As data science is an extremely broad field, it is likely that we may have missed a few phrases that may be considered by others to be skill phrases, due to lack of knowledge about certain skills. We did our best to be as thorough as possible in labeling the phrases, understanding that there might be some mislabeling.
The labeled phrases were used to train an LSTM model that can determine if a noun phrase is a skill. Short for long short-term memory, LSTMs are deep neural networks that are commonly used to perform predictions on sequences of data such as audio, video, and text.
We now have a model that can be used to extract skills from a job description. Here's some of the skill phrases the model identified with high confidence.
"solid professional software engineering skills"
"skills experience etl experience aws"
"data warehouse and analytics solutions"
"probability"
"data mining concepts"
"bigquery hive hadoop hdfs"
And some the phrases not classified as a skill:
"aseptic and non aseptic drug"
"scientific application prototyping"
"boxing day"
"related query engines"
Visualizing Extracted Skills
With a skill extraction model in hand, we were now able to discover the most common skills employers for in their new hires.
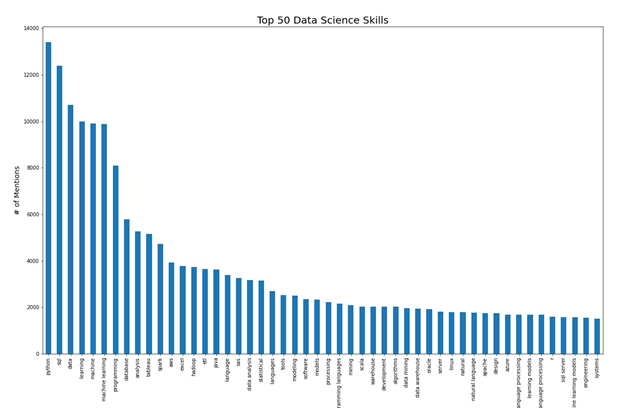
Unigram, bigram, and trigram tokens were produced from the skill phrases identified by model. These tokens are sequences of 1-3 words that are adjacent to each other in the text. We counted the number of job descriptions each token was mentioned in and produced a figure of the top 50 data science skill terms.
https://cdn.gx-staging.com/Top_50_data_Science_Skills.png
{kind=link}
Overall python, sql, and machine learning appear to be the most essential skills sought by employers hiring data science professionals.
The next three figures show the most common skill terms used in job listings for three different data roles.
The first figure below shows the top terms for data scientist job listings.
https://cdn.gx-staging.com/Top_Data_Science_Job_Description_Skills.png
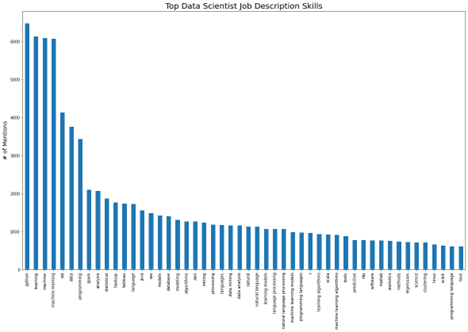{kind=link}
The next figure shows the top terms for data engineering job descriptions.
https://cdn.gx-staging.com/Top_Data_Engineering_Job_Description_Skills.png
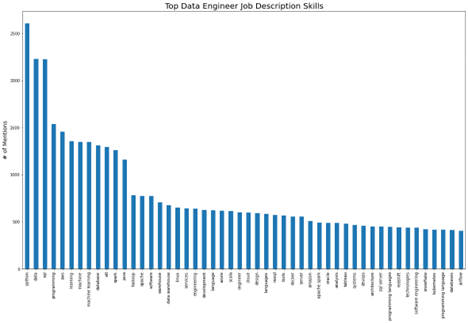{kind=link}
And for data analyst job descriptions:
https://cdn.gx-staging.com/Top_Data_Analyst_Job_Description_Skills.png
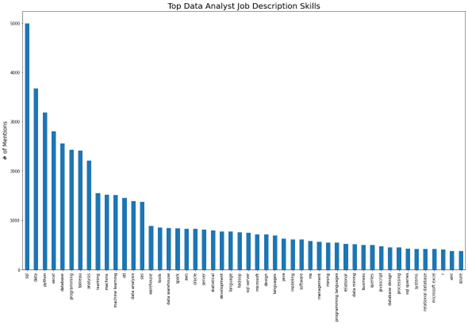{kind=link}
Data scientists, data engineers, and data analysts have a lot of skills that they share. Depending on the nature of the work that is being done, these roles can require many if not all the same set of skills. This makes data science confusing for many aspiring professionals. They are often not sure which skills to focus on for certain roles.
https://cdn.gx-staging.com/Small_Word_Cloud_By_Job_Name.png
{kind=link}
Through the power of statistical testing, we identified skill terms that are associated with different data science roles.
We generated the word clouds above by performing chi squared tests on the frequency counts of each skill term in job descriptions for data scientists, data engineers, and data analysts. Looking at the charts we can discern the following distinctions between skillsets for the three roles:
- The Data Analyst skillset center around reporting and business analytics tools such as Excel, Tableau, PowerBI, and Qlikview.
- The skills of a Data Scientist center around machine learning and other sophisticated data analysis methods.
- The Data Engineer skillset leans heavily on programming languages, tools, and frameworks that enable the development of data pipelines and scalable software solutions.
Both the skill extractor and the problem extractor are available on the Marketplace. Create a free account on GravityAI and try them out today! You can play around with the data science job description parser we created by clicking HERE.